Generative models have the potential to accelerate key steps in the discovery of novel molecular therapeutics and materials. Diffusion models have recently emerged as a powerful approach, excelling at unconditional sample generation and, with data-driven guidance, conditional generation within their training distribution. Reliably sampling from optimal regions beyond the training data, however, remains an open challenge—with current methods predominantly focusing on modifying the diffusion process itself. Here, we explore a different approach and present a simple plug-and-play regularization framework that leverages unlabeled data and smoothness constraints to improve the out-of-distribution generalization of guided diffusion models. Our method is probabilistically motivated and leads to substantial performance gains across various settings, including continuous, discrete, and graph-structured diffusion processes. We demonstrate significant improvements in performance for applications in chemistry, materials science, and protein design.
@inproceedings{klarner2024guided,title={Domain-Aware Guidance for Out-of-Distribution Molecular and Protein Design},author={Klarner, Leo and Rudner, Tim G. J. and Garrett M. Morris, Charlotte Deane, Yee Whye Teh.},booktitle={Proceedings of the 41th International Conference on Machine Learning},year={2024},series={Proceedings of Machine Learning Research},publisher={PMLR},}
Non-Vacuous Generalization Bounds for Large Language Models
Sanae Lotfi, Marc Finzi, Yilun Kuang, Tim G. J. Rudner, Micah Goldblum, and Andrew Gordon Wilson
International Conference on Machine Learning(ICML), 2024
Modern language models can contain billions of parameters, raising the question of whether they can generalize beyond the training data or simply regurgitate their training corpora. We provide the first non-vacuous generalization bounds for pretrained large language models (LLMs), indicating that language models are capable of discovering regularities that generalize to unseen data. In particular, we derive a compression bound that is valid for the unbounded log-likelihood loss, and we extend the bound to handle subsampling, accelerating bound computation on massive datasets. To achieve the extreme level of compression required for non-vacuous generalization bounds, we devise SubLoRA, a low-dimensional non-linear parameterization. Using this approach, we find that larger models have better generalization bounds and are more compressible than smaller models.
@inproceedings{lotfi2024pacllm,title={Non-Vacuous Generalization Bounds for Large Language Models},author={Lotfi, Sanae and Finzi, Marc and Kuang, Yilun and Rudner, Tim G. J. and Goldblum, Micah and Wilson, Andrew Gordon},booktitle={Proceedings of the 41th International Conference on Machine Learning},year={2024},series={Proceedings of Machine Learning Research},publisher={PMLR},}
Position Paper: Bayesian Deep Learning in the Age of Large-Scale AI
Theodore Papamarkou, Maria Skoularidou, Konstantina Palla, Laurence Aitchison, Julyan Arbel, David Dunson, Maurizio Filippone, Vincent Fortuin, Philipp Hennig, Jose Miguel Hernandez Lobato, Aliaksandr Hubin, Alexander Immer, Theofanis Karaletsos, Mohammad Emtiyaz Khan, Agustinus Kristiadi, Yingzhen Li, Stephan Mandt, Christopher Nemeth, Michael A. Osborne, Tim G. J. Rudner, David Rügamer, Yee Whye Teh, Max Welling, Andrew Gordon Wilson, and Ruqi Zhang
International Conference on Machine Learning(ICML), 2024
In the current landscape of deep learning research, there is a predominant emphasis on achieving high predictive accuracy in supervised tasks involving large image and language datasets. However, a broader perspective reveals a multitude of overlooked metrics, tasks, and data types, such as uncertainty, active and continual learning, and scientific data, that demand attention. Bayesian deep learning (BDL) constitutes a promising avenue, offering advantages across these diverse settings. This paper posits that BDL can elevate the capabilities of deep learning. It revisits the strengths of BDL, acknowledges existing challenges, and highlights some exciting research avenues aimed at addressing these obstacles. Looking ahead, the discussion focuses on possible ways to combine large-scale foundation models with BDL to unlock their full potential.
@inproceedings{papamarkou2024bayespos,title={Position Paper: Bayesian Deep Learning in the Age of Large-Scale AI},author={Papamarkou, Theodore and Skoularidou, Maria and Palla, Konstantina and Aitchison, Laurence and Arbel, Julyan and Dunson, David and Filippone, Maurizio and Fortuin, Vincent and Hennig, Philipp and Lobato, Jose Miguel Hernandez and Hubin, Aliaksandr and Immer, Alexander and Karaletsos, Theofanis and Khan, Mohammad Emtiyaz and Kristiadi, Agustinus and Li, Yingzhen and Mandt, Stephan and Nemeth, Christopher and Osborne, Michael A. and Rudner, Tim G. J. and Rügamer, David and Teh, Yee Whye and Welling, Max and Wilson, Andrew Gordon and Zhang, Ruqi},booktitle={Proceedings of the 41th International Conference on Machine Learning},year={2024},series={Proceedings of Machine Learning Research},publisher={PMLR},}
Pre-trained Text-to-Image Diffusion Models Are Versatile Representation Learners for Control
Gunshi Gupta, Karmesh Yadav, Yarin Gal, Dhruv Batra, Zsolt Kira, Cong Lu, and Tim G. J. Rudner
ICLR Workshop on Generative Models for Decision Making, 2024
Vision- and language-guided embodied AI requires a fine-grained understanding of the physical world through language and visual inputs. Such capabilities are difficult to learn solely from task-specific data, which has led to the emergence of pre-trained vision-language models as a tool for transferring representations learned from internet-scale data to downstream tasks and new domains. However, commonly used contrastively trained representations such as in CLIP have been shown to fail at enabling embodied agents to gain sufficiently fine-grained scene understanding—a capability vital for control. To address this shortcoming, we consider representations from pre-trained text-to-image diffusion models, which are explicitly optimized to generate image from text prompts and as such, contain text-conditioned representations that reflect highly fine-grained visuo-spatial information. Using pre-trained text-to-image diffusion models, we construct \em \ouralgolong which allow learning downstream control policies that generalize to complex, open-ended environments. We show that policies learned using \ouralgolong are competitive with state-of-the-art approaches on a broad range of simulated control tasks and exhibit high success rates on difficult control tasks that require generalization to unseen objects at test time. Most notably, we show that \ouralgolong enable learning policies that exhibit state-of-the-art performance on OVMM, a difficult open-vocabulary navigation benchmark.
@inproceedings{gupta2024scr,title={Pre-trained Text-to-Image Diffusion Models Are Versatile Representation Learners for Control},author={Gupta, Gunshi and Yadav, Karmesh and Gal, Yarin and Batra, Dhruv and Kira, Zsolt and Lu, Cong and Rudner, Tim G. J.},booktitle={ICLR Workshop on Generative Models for Decision Making},year={2024},}
Mind the GAP: Improving Robustness to Subpopulation Shifts with Group-Aware Priors
Tim G. J. Rudner, Ya Shi Zhang, Andrew Gordon Wilson, and Julia Kempe
International Conference on Artificial Intelligence and Statistics(AISTATS), 2024
Machine learning models often perform poorly under subpopulation shifts in the data distribution. Developing methods that allow machine learning models to better generalize to such shifts is crucial for safe deployment in real-world settings. In this paper, we develop a family of group-aware prior (GAP) distributions over neural network parameters that explicitly favor models that generalize well under subpopulation shifts. We design a simple group-aware prior that only requires access to a small set of data with group information and demonstrate that training with this prior yields state-of-the-art performance—even when only retraining the final layer of a previously trained non-robust model. Group aware-priors are conceptually simple, complementary to existing approaches, such as attribute pseudo labeling and data reweighting, and open up promising new avenues for harnessing Bayesian inference to enable robustness to subpopulation shifts.
@inproceedings{rudner2024gap,title={Mind the GAP: Improving Robustness to Subpopulation Shifts with Group-Aware Priors},author={Rudner, Tim G. J. and Zhang, Ya Shi and Wilson, Andrew Gordon and Kempe, Julia},booktitle={Proceedings of The 26th International Conference on Artificial Intelligence and Statistics},year={2024},}
A Study of Bayesian Neural Network Surrogates for Bayesian Optimization
Yucen Lily Li, Tim G. J. Rudner, and Andrew Gordon Wilson
International Conference on Learning Representations(ICLR), 2024
Bayesian optimization is a highly efficient approach to optimizing objective functions which are expensive to query. These objectives are typically represented by Gaussian process (GP) surrogate models which are easy to optimize and support exact inference. While standard GP surrogates have been well-established in Bayesian optimization, Bayesian neural networks (BNNs) have recently become practical function approximators, with many benefits over standard GPs such as the ability to naturally handle non-stationarity and learn representations for high-dimensional data. In this paper, we study BNNs as alternatives to standard GP surrogates for optimization. We consider a variety of approximate inference procedures for finite-width BNNs, including high-quality Hamiltonian Monte Carlo, low-cost stochastic MCMC, and heuristics such as deep ensembles. We also consider infinite-width BNNs and partially stochastic models such as deep kernel learning. We evaluate this collection of surrogate models on diverse problems with varying dimensionality, number of objectives, non-stationarity, and discrete and continuous inputs. We find: (i) the ranking of methods is highly problem dependent, suggesting the need for tailored inductive biases; (ii) HMC is the most successful approximate inference procedure for fully stochastic BNNs; (iii) full stochasticity may be unnecessary as deep kernel learning is relatively competitive; (iv) infinite-width BNNs are particularly promising, especially in high dimensions.
@inproceedings{li2024bostudy,title={A Study of Bayesian Neural Network Surrogates for Bayesian Optimization},author={Li, Yucen Lily and Rudner, Tim G. J. and Wilson, Andrew Gordon},booktitle={Twelfth International Conference on Learning Representations},year={2024},}
Uncertainty-Aware Priors for Fine-Tuning Pre-trained Vision and Language Models
Tim G. J. Rudner, Xiang Pan, Yucen Lily Li, Ravid Shwartz-Ziv, and Andrew Gordon Wilson
Fine-tuning off-the-shelf pre-trained neural networks has become the default starting point for a wide range of challenging prediction tasks—especially in computer vision and natural language processing, where pre-trained models trained on millions or even billions of data points are publicly available and can be fine-tuned with a moderate compute budget. However, while fine-tuned models have been shown to significantly improve predictive performance in several respects compared to models trained from scratch, they can exhibit poor calibration and fail to reliably identify challenging distribution shifts. In this paper, we improve uncertainty quantification in fine-tuned models by constructing an uncertainty-aware fine-tuning prior and deriving a tractable variational objective for inference. The prior assigns high probability density to parameters that induce predictive functions with high uncertainty on data points that are meaningfully different from the data used for fine-tuning. We evaluate models trained with this prior on different transfer learning tasks and show that fine-tuning with uncertainty-aware priors significantly improves calibration, selective prediction, and semantic shift detection on computer vision and natural language classification tasks.
@inproceedings{rudner2024uap,title={Uncertainty-Aware Priors for Fine-Tuning Pre-trained Vision and Language Models},author={Rudner, Tim G. J. and Pan, Xiang and Li, Yucen Lily and Shwartz-Ziv, Ravid and Wilson, Andrew Gordon},booktitle={Preprint},year={2024},}
2023
Should We Learn Most Likely Functions or Parameters?
Shikai Qiu*, Tim G. J. Rudner*, Sanyam Kapoor, and Andrew Gordon Wilson
Advances in Neural Information Processing Systems(NeurIPS), 2023
Standard regularized training procedures correspond to maximizing a posterior distribution over parameters, known as maximum a posteriori (MAP) estimation. However, model parameters are of interest only insomuch as they combine with the functional form of a model to provide a function that can make good predictions. Moreover, the most likely parameters under the parameter posterior do not generally correspond to the most likely function induced by the parameter posterior. In fact, we can re-parametrize a model such that any setting of parameters can maximize the parameter posterior. As an alternative, we investigate the benefits and drawbacks of directly estimating the most likely function implied by the model and the data. We show that this procedure leads to pathological solutions when using neural networks and prove conditions under which the procedure is well-behaved, as well as a scalable approximation. Under these conditions, we find that function-space MAP estimation can lead to flatter minima, better generalization, and improved robustness to overfitting.
@inproceedings{rudner2023fsmap,title={Should We Learn Most Likely Functions or Parameters?},author={Qiu, Shikai and Rudner, Tim G. J. and Kapoor, Sanyam and Wilson, Andrew Gordon},booktitle={Advances in Neural Information Processing Systems 36},year={2023},}
Visual Explanations of Image-Text Representations via Multi-Modal Information Bottleneck Attribution
Ying Wang*, Tim G. J. Rudner*, and Andrew Gordon Wilson
Advances in Neural Information Processing Systems(NeurIPS), 2023
Vision-language pretrained models have seen remarkable success, but their application to safety-critical settings is limited by their lack of interpretability. To improve the interpretability of vision-language models such as CLIP, we propose a multi-modal information bottleneck (M2IB) approach that learns latent representations that compress irrelevant information while preserving relevant visual and textual features. We demonstrate how M2IB can be applied to attribution analysis of vision-language pretrained models, increasing attribution accuracy and improving the interpretability of such models when applied to safety-critical domains such as healthcare. Crucially, unlike commonly used unimodal attribution methods, M2IB does not require ground truth labels, making it possible to audit representations of vision-language pretrained models when multiple modalities but no ground truth data is available. Using CLIP as an example, we demonstrate the effectiveness of M2IB attribution and show that it outperforms gradient-based, perturbation-based, and attention-based attribution methods both qualitatively and quantitatively.
@inproceedings{wang2023m2ib,title={Visual Explanations of Image-Text Representations via Multi-Modal Information Bottleneck Attribution},author={Wang, Ying and Rudner, Tim G. J. and Wilson, Andrew Gordon},booktitle={Advances in Neural Information Processing Systems 36},year={2023},}
Protein Design with Guided Discrete Diffusion
Nate Gruver, Samuel Stanton, Nathan C. Frey, Tim G. J. Rudner, Isidro Hotzel, Julien Lafrance-Vanasse, Arvind Rajpal, Kyunghyun Cho, and Andrew Gordon Wilson
Advances in Neural Information Processing Systems(NeurIPS), 2023
A popular approach to protein design is to combine a generative model with a discriminative model for conditional sampling. The generative model samples plausible sequences while the discriminative model guides a search for sequences with high fitness. Given its broad success in conditional sampling, classifier-guided diffusion modeling is a promising foundation for protein design, leading many to develop guided diffusion models for structure with inverse folding to recover sequences. In this work, we propose diffusioN Optimized Sampling (NOS), a guidance method for discrete diffusion models that follows gradients in the hidden states of the denoising network. NOS makes it possible to perform design directly in sequence space, circumventing significant limitations of structure-based methods, including scarce data and challenging inverse design. Moreover, we use NOS to generalize LaMBO, a Bayesian optimization procedure for sequence design that facilitates multiple objectives and edit-based constraints. The resulting method, LaMBO-2, enables discrete diffusions and stronger performance with limited edits through a novel application of saliency maps. We apply LaMBO-2 to a real-world protein design task, optimizing antibodies for higher expression yield and binding affinity to several therapeutic targets under locality and developability constraints, attaining a 99% expression rate and 40% binding rate in exploratory in vitro experiments.
@inproceedings{gruver2023nos,title={Protein Design with Guided Discrete Diffusion},author={Gruver, Nate and Stanton, Samuel and Frey, Nathan C. and Rudner, Tim G. J. and Hotzel, Isidro and Lafrance-Vanasse, Julien and Rajpal, Arvind and Cho, Kyunghyun and Wilson, Andrew Gordon},booktitle={Advances in Neural Information Processing Systems 36},year={2023},}
An Information-Theoretic Perspective on Variance-Invariance-Covariance Regularization
Ravid Shwartz-Ziv, Randall Balestriero, Kenji Kawaguchi, Tim G. J. Rudner, and Yann LeCun
Advances in Neural Information Processing Systems(NeurIPS), 2023
Variance-Invariance-Covariance Regularization (VICReg) is a self-supervised learning (SSL) method that has shown promising results on a variety of tasks. However, the fundamental mechanisms underlying VICReg remain unexplored. In this paper, we present an information-theoretic perspective on the VICReg objective. We begin by deriving information-theoretic quantities for deterministic networks as an alternative to unrealistic stochastic network assumptions. We then relate the optimization of the VICReg objective to mutual information optimization, highlighting underlying assumptions and facilitating a constructive comparison with other SSL algorithms and derive a generalization bound for VICReg, revealing its inherent advantages for downstream tasks. Building on these results, we introduce a family of SSL methods derived from information-theoretic principles that outperform existing SSL techniques.
@inproceedings{shwartz2023vicreg,title={An Information-Theoretic Perspective on Variance-Invariance-Covariance Regularization},author={Shwartz-Ziv, Ravid and Balestriero, Randall and Kawaguchi, Kenji and Rudner, Tim G. J. and LeCun, Yann},booktitle={Advances in Neural Information Processing Systems 36},year={2023},}
Informative Priors Improve the Reliability of Multimodal Clinical Data Classification
Julian Lechuga Lopez, Tim G. J. Rudner, and Farah Shamout
Machine Learning for Health Symposium Findings(ML4H), 2023
Machine learning-aided clinical decision support has the potential to significantly improve patient care. However, existing efforts in this domain for principled quantification of uncertainty have largely been limited to applications of ad-hoc solutions that do not consistently improve reliability. In this work, we consider stochastic neural networks and design a tailor-made multimodal data-driven (M2D2) prior distribution over network parameters. We use simple and scalable Gaussian mean-field variational inference to train a Bayesian neural network using the M2D2 prior. We train and evaluate the proposed approach using clinical time-series data in MIMIC-IV and corresponding chest X-ray images in MIMIC-CXR for the classification of acute care conditions. Our empirical results show that the proposed method produces a more reliable predictive model compared to deterministic and Bayesian neural network baselines.
@inproceedings{lechuga2023m2d2,title={Informative Priors Improve the Reliability of Multimodal Clinical Data Classification},author={Lopez, Julian Lechuga and Rudner, Tim G. J. and Shamout, Farah},booktitle={Machine Learning for Health Symposium Findings},year={2023},}
Function-Space Regularization in Neural Networks: A Probabilistic Perspective
Tim G. J. Rudner, Sanyam Kapoor, Shikai Qiu, and Andrew Gordon Wilson
International Conference on Machine Learning(ICML), 2023
Parameter-space regularization in neural network optimization is a fundamental tool for improving generalization. However, standard parameter-space regularization methods make it challenging to encode explicit preferences about desired predictive functions into neural network training. In this work, we approach regularization in neural networks from a probabilistic perspective and show that by viewing parameter-space regularization as specifying an empirical prior distribution over the model parameters, we can derive a probabilistically well-motivated regularization technique that allows explicitly encoding information about desired predictive functions into neural network training. This method—which we refer to as function-space empirical Bayes (FS-EB)—includes both parameter- and function-space regularization, is mathematically simple, easy to implement, and incurs only minimal computational overhead compared to standard regularization techniques. We evaluate the utility of this regularization technique empirically and demonstrate that the proposed method leads to near-perfect semantic shift detection, highly-calibrated predictive uncertainty estimates, successful task adaption from pre-trained models, and improved generalization under covariate shift
@inproceedings{rudner2023fseb,title={{F}unction-{S}pace {R}egularization in {N}eural {N}etworks: {A} {P}robabilistic {P}erspective},author={Rudner, Tim G. J. and Kapoor, Sanyam and Qiu, Shikai and Wilson, Andrew Gordon},booktitle={Proceedings of the 40th International Conference on Machine Learning},year={2023},series={Proceedings of Machine Learning Research},publisher={PMLR},}
Drug Discovery under Covariate Shift with Domain-Informed Prior Distributions over Functions
Leo Klarner, Tim G. J. Rudner, Michael Reutlinger, Torsten Schindler, Garrett M. Morris, Charlotte Deane, and Yee Whye Teh
International Conference on Machine Learning(ICML), 2023
Accelerating the discovery of novel and more effective therapeutics is an important pharmaceutical problem in which deep learning is playing an increasingly significant role. However, real-world drug discovery tasks are often characterized by a scarcity of labeled data and significant covariate shift—a setting that poses a challenge to standard deep learning methods. In this paper, we present Q-SAVI, a probabilistic model able to address these challenges by encoding explicit prior knowledge of the data-generating process into a prior distribution over functions, presenting researchers with a transparent and probabilistically principled way to encode data-driven modeling preferences. Building on a novel, gold-standard bioactivity dataset that facilitates a meaningful comparison of models in an extrapolative regime, we explore different approaches to induce data shift and construct a challenging evaluation setup. We then demonstrate that using Q-SAVI to integrate contextualized prior knowledge of drug-like chemical space into the modeling process affords substantial gains in predictive accuracy and calibration, outperforming a broad range of state-of-the-art self-supervised pre-training and domain adaptation techniques.
@inproceedings{klarner2023qsavi,title={{D}rug {D}iscovery {u}nder {C}ovariate {S}hift {w}ith {D}omain-{I}nformed {P}rior {D}istributions {o}ver {F}unctions},author={Klarner, Leo and Rudner, Tim G. J. and Reutlinger, Michael and Schindler, Torsten and Morris, Garrett M. and Deane, Charlotte and Teh, Yee Whye},booktitle={Proceedings of the 40th International Conference on Machine Learning},year={2023},series={Proceedings of Machine Learning Research},publisher={PMLR},}
Attacking Bayes: Are Bayesian Neural Networks Inherently Robust?
Yunzhen Feng, Tim G. J. Rudner, Nikolaos Tsilivis, and Julia Kempe
Symposium on Advances in Approximate Bayesian Inference(AABI), 2023
This work examines the claim in recent work that Bayesian neural networks (BNNs) are inherently robust to adversarial perturbations. To study this question, we investigate whether it is possible to successfully break state-of-the-art BNN inference methods and prediction pipelines using even relatively unsophisticated attacks for three tasks: (1) label prediction under the posterior predictive mean, (2) adversarial example detection with Bayesian predictive uncertainty, and (3) semantic shift detection. We find that BNNs trained with state-of-the-art approximate inference methods, and even with HMC inference, are highly susceptible to adversarial attacks and identify various conceptual and experimental errors in previous works that claimed inherent adversarial robustness of BNNs. We conclusively demonstrate that BNNs and uncertainty-aware Bayesian prediction pipelines are not inherently robust against adversarial attacks and open up avenues for the development of Bayesian defenses for Bayesian prediction pipelines.
@inproceedings{feng2023attackingbayes,title={Attacking Bayes: Are Bayesian Neural Networks Inherently Robust?},author={Feng, Yunzhen and Rudner, Tim G. J. and Tsilivis, Nikolaos and Kempe, Julia},booktitle={Fifth Symposium on Advances in Approximate Bayesian Inference},year={2023},}
Challenges and Opportunities in Offline Reinforcement Learning from Visual Observations
Cong Lu, Philip J. Ball, Tim G. J. Rudner, Jack Parker-Holder, Michael A. Osborne, and Yee Whye Teh
Transactions on Machine Learning Research(TMLR), 2023
Offline reinforcement learning has shown great promise in leveraging large pre-collected datasets for policy learning, allowing agents to forgo often-expensive online data collection. However, offline reinforcement learning from visual observations with continuous action spaces remains under-explored, with a limited understanding of the key challenges in this complex domain. In this paper, we establish simple baselines for continuous control in the visual domain and introduce a suite of benchmarking tasks for offline reinforcement learning from visual observations designed to better represent the data distributions present in real-world offline RL problems and guided by a set of desiderata for offline RL from visual observations, including robustness to visual distractions and visually identifiable changes in dynamics. Using this suite of benchmarking tasks, we show that simple modifications to two popular vision-based online reinforcement learning algorithms, DreamerV2 and DrQ-v2, suffice to outperform existing offline RL methods and establish competitive baselines for continuous control in the visual domain. We rigorously evaluate these algorithms and perform an empirical evaluation of the differences between state-of-the-art model-based and model-free offline RL methods for continuous control from visual observations. All code and data used in this evaluation are open-sourced to facilitate progress in this domain.
@inproceedings{lu2023challenges,title={{C}hallenges and {O}pportunities in {O}ffline {R}einforcement {L}earning from {V}isual {O}bservations},author={Lu, Cong and Ball, Philip J. and Rudner, Tim G. J. and Parker-Holder, Jack and Osborne, Michael A. and Teh, Yee Whye},year={2023},booktitle={Transactions on Machine Learning Research},issn={2835-8856},}
Can Active Sampling Reduce Causal Confusion in Offline Reinforcement Learning?
Gunshi Gupta, Tim G. J. Rudner, Rowan Thomas McAllister, Adrien Gaidon, and Yarin Gal
Conference on Causal Learning and Reasoning(CLeaR), 2023
Offline reinforcement learning has shown great promise in leveraging large pre-collected datasets for policy learning, allowing agents to forgo often-expensive online data collection. However, offline reinforcement learning from visual observations with continuous action spaces remains under-explored, with a limited understanding of the key challenges in this complex domain. In this paper, we establish simple baselines for continuous control in the visual domain and introduce a suite of benchmarking tasks for offline reinforcement learning from visual observations designed to better represent the data distributions present in real-world offline RL problems and guided by a set of desiderata for offline RL from visual observations, including robustness to visual distractions and visually identifiable changes in dynamics. Using this suite of benchmarking tasks, we show that simple modifications to two popular vision-based online reinforcement learning algorithms, DreamerV2 and DrQ-v2, suffice to outperform existing offline RL methods and establish competitive baselines for continuous control in the visual domain. We rigorously evaluate these algorithms and perform an empirical evaluation of the differences between state-of-the-art model-based and model-free offline RL methods for continuous control from visual observations. All code and data used in this evaluation are open-sourced to facilitate progress in this domain.
@inproceedings{gupta2023activesampling,title={{C}an {A}ctive {S}ampling {R}educe {C}ausal {C}onfusion in {O}ffline {R}einforcement {L}earning?},author={Gupta, Gunshi and Rudner, Tim G. J. and McAllister, Rowan Thomas and Gaidon, Adrien and Gal, Yarin},booktitle={Proceedings of the 2nd Conference on Causal Learning and Reasoning},year={2023},series={Proceedings of Machine Learning Research},publisher={PMLR},}
2022
Tractable Function-Space Variational Inference in Bayesian Neural Networks
Tim G. J. Rudner, Zonghao Chen, Yee Whye Teh, and Yarin Gal
Advances in Neural Information Processing Systems(NeurIPS), 2022
Reliable predictive uncertainty estimation plays an important role in enabling the deployment of neural networks to safety-critical settings. A popular approach for estimating the predictive uncertainty of neural networks is to define a prior distribution over the network parameters, infer an approximate posterior distribution, and use it to make stochastic predictions. However, explicit inference over neural network parameters makes it difficult to incorporate meaningful prior information about the data-generating process into the model. In this paper, we pursue an alternative approach. Recognizing that the primary object of interest in most settings is the distribution over functions induced by the posterior distribution over neural network parameters, we frame Bayesian inference in neural networks explicitly as inferring a posterior distribution over functions and propose a scalable function-space variational inference method that allows incorporating prior information and results in reliable predictive uncertainty estimates. We show that the proposed method leads to state-of-the-art uncertainty estimation and predictive performance on a range of prediction tasks and demonstrate that it performs well on a challenging safety-critical medical diagnosis task in which reliable uncertainty estimation is essential.
@inproceedings{rudner2022fsvi,title={{T}ractable {F}unction-{S}pace {V}ariational {I}nference in {B}ayesian {N}eural {N}etworks},author={Rudner, Tim G. J. and Chen, Zonghao and Teh, Yee Whye and Gal, Yarin},booktitle={Advances in Neural Information Processing Systems 35},year={2022},}
A Neural Tangent Kernel Perspective on Function-Space Regularization in Neural Networks
Zonghao Chen, Xupeng Shi, Tim G. J. Rudner, Qixuan Feng, Weizhong Zhang, and Tong Zhang
NeurIPS Workshop on Optimization for Machine Learning, 2022
Regularization can help reduce the gap between training and test error by systematically limiting model complexity. Popular regularization techniques such as L2 weight regularization act directly on the network parameters but do not explicitly take into account how the interplay between the parameters and the network architecture may affect the induced predictive functions. To address this shortcoming, we propose a simple technique for effective function-space regularization. Drawing on the result that fully-trained wide multi-layer perceptrons are equivalent to kernel regression under the Neural Tangent Kernel (NTK), we propose to approximate the norm of neural network functions by the reproducing kernel Hilbert space norm under the NTK and use it as a function-space regularizer. We prove that neural networks trained using this regularizer are arbitrarily close to kernel ridge regression solutions under the NTK. Furthermore, we provide a generalization error bound under the proposed regularizer and empirically demonstrate improved generalization and state-of-the-art performance on downstream tasks where effective regularization on the induced space of functions is essential.
@inproceedings{chen2022ntk,title={A Neural Tangent Kernel Perspective on Function-Space Regularization in Neural Networks},author={Chen, Zonghao and Shi, Xupeng and Rudner, Tim G. J. and Feng, Qixuan and Zhang, Weizhong and Zhang, Tong},booktitle={NeurIPS Workshop on Optimization for Machine Learning},year={2022},}
Continual Learning via Sequential Function-Space Variational Inference
Tim G. J. Rudner, Freddie Bickford Smith, Qixuan Feng, Yee Whye Teh, and Yarin Gal
International Conference on Machine Learning(ICML), 2022
Sequential Bayesian inference over predictive functions is a natural framework for continual learning from streams of data. However, applying it to neural networks has proved challenging in practice. Addressing the drawbacks of existing techniques, we propose an optimization objective derived by formulating continual learning as sequential function-space variational inference. In contrast to existing methods that regularize neural network parameters directly, this objective allows parameters to vary widely during training, enabling better adaptation to new tasks. Compared to objectives that directly regularize neural network predictions, the proposed objective allows for more flexible variational distributions and more effective regularization. We demonstrate that, across a range of task sequences, neural networks trained via sequential function-space variational inference achieve better predictive accuracy than networks trained with related methods while depending less on maintaining a set of representative points from previous tasks.
@inproceedings{rudner2022sfsvi,author={Rudner, Tim G. J. and Smith, Freddie Bickford and Feng, Qixuan and Teh, Yee Whye and Gal, Yarin},title={{C}ontinual {L}earning via {S}equential {F}unction-{S}pace {V}ariational {I}nference},booktitle={Proceedings of the 39th International Conference on Machine Learning},year={2022},series={Proceedings of Machine Learning Research},publisher={PMLR},}
Plex: Towards Reliability Using Pretrained Large Model Extensions
Dustin Tran, Jeremiah Liu, Michael W. Dusenberry, Du Phan, Mark Collier, Jie Ren, Kehang Han, Zi Wang, Zelda Mariet, Huiyi Hu, Neil Band, Tim G. J. Rudner, Karan Singhal, Zachary Nado, Joost Amersfoort, Andreas Kirsch, Rodolphe Jenatton, Nithum Thain, Honglin Yuan, Kelly Buchanan, Kevin Murphy, D. Sculley, Yarin Gal, Zoubin Ghahramani, Jasper Snoek, and Balaji Lakshminarayanan
ICML Workshop on Pre-training: Perspectives, Pitfalls, and Paths Forward, 2022
A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models’ abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex’s capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
@inproceedings{tran2022plex,author={Tran, Dustin and Liu, Jeremiah and Dusenberry, Michael W. and Phan, Du and Collier, Mark and Ren, Jie and Han, Kehang and Wang, Zi and Mariet, Zelda and Hu, Huiyi and Band, Neil and Rudner, Tim G. J. and Singhal, Karan and Nado, Zachary and van Amersfoort, Joost and Kirsch, Andreas and Jenatton, Rodolphe and Thain, Nithum and Yuan, Honglin and Buchanan, Kelly and Murphy, Kevin and Sculley, D. and Gal, Yarin and Ghahramani, Zoubin and Snoek, Jasper and Lakshminarayanan, Balaji},title={{P}lex: {T}owards {R}eliability {U}sing {P}retrained {L}arge {M}odel {E}xtensions},year={2022},booktitle={ICML Workshop on Pre-training: Perspectives, Pitfalls, and Paths Forward},}
2021
Outcome-Driven Reinforcement Learning via Variational Inference
Tim G. J. Rudner*, Vitchyr H. Pong*, Rowan McAllister, Yarin Gal, and Sergey Levine
Advances in Neural Information Processing Systems(NeurIPS), 2021
While reinforcement learning algorithms provide automated acquisition of optimal policies, practical application of such methods requires a number of design decisions, such as manually designing reward functions that not only define the task, but also provide sufficient shaping to accomplish it. In this paper, we view reinforcement learning as inferring policies that achieve desired outcomes, rather than as a problem of maximizing rewards. To solve this inference problem, we establish a novel variational inference formulation that allows us to derive a well-shaped reward function which can be learned directly from environment interactions. From the corresponding variational objective, we also derive a new probabilistic Bellman backup operator and use it to develop an off-policy algorithm to solve goal-directed tasks. We empirically demonstrate that this method eliminates the need to hand-craft reward functions for a suite of diverse manipulation and locomotion tasks and leads to effective goal-directed behaviors.
@inproceedings{rudner2021odrl,title={{O}utcome-{D}riven {R}einforcement {L}earning via {V}ariational {I}nference},author={Rudner, Tim G. J. and Pong, Vitchyr H. and McAllister, Rowan and Gal, Yarin and Levine, Sergey},booktitle={Advances in Neural Information Processing Systems 34},year={2021},}
On Pathologies in KL-Regularized Reinforcement Learning from Expert Demonstrations
Tim G. J. Rudner*, Cong Lu*, Michael A. Osborne, Yarin Gal, and Yee Whye Teh
Advances in Neural Information Processing Systems(NeurIPS), 2021
KL-regularized reinforcement learning from expert demonstrations has proved successful in improving the sample efficiency of deep reinforcement learning algorithms, allowing them to be applied to challenging physical real-world tasks. However, we show that KL-regularized reinforcement learning with behavioral reference policies derived from expert demonstrations can suffer from pathological training dynamics that can lead to slow, unstable, and suboptimal online learning. We show empirically that the pathology occurs for commonly chosen behavioral policy classes and demonstrate its impact on sample efficiency and online policy performance. Finally, we show that the pathology can be remedied by non-parametric behavioral reference policies and that this allows KL-regularized reinforcement learning to significantly outperform state-of-the-art approaches on a variety of challenging locomotion and dexterous hand manipulation tasks.
@inproceedings{rudner2021pathologies,title={{O}n {P}athologies in {KL}-{R}egularized {R}einforcement {L}earning from {E}xpert {D}emonstrations},author={Rudner, Tim G. J. and Lu, Cong and Osborne, Michael A. and Gal, Yarin and Teh, Yee Whye},booktitle={Advances in Neural Information Processing Systems 34},year={2021},}
Benchmarking Bayesian Deep Learning on Diabetic Retinopathy Detection Tasks
Neil Band*, Tim G. J. Rudner*, Qixuan Feng, Angelos Filos, Zachary Nado, Michael W. Dusenberry, Ghassen Jerfel, Dustin Tran, and Yarin Gal
Advances in Neural Information Processing Systems(NeurIPS), 2021
Bayesian deep learning seeks to equip deep neural networks with the ability to precisely quantify their predictive uncertainty, and has promised to make deep learning more reliable for safety-critical real-world applications. Yet, existing Bayesian deep learning methods fall short of this promise; new methods continue to be evaluated on unrealistic test beds that do not reflect the complexities of downstream real-world tasks that would benefit most from reliable uncertainty quantification. We propose the RETINA Benchmark, a set of real-world tasks that accurately reflect such complexities and are designed to assess the reliability of predictive models in safety-critical scenarios. Specifically, we curate two publicly available datasets of high-resolution human retina images exhibiting varying degrees of diabetic retinopathy, a medical condition that can lead to blindness, and use them to design a suite of automated diagnosis tasks that require reliable predictive uncertainty quantification. We use these tasks to benchmark well-established and state-of-the-art Bayesian deep learning methods on task-specific evaluation metrics. We provide an easy-to-use codebase for fast and easy benchmarking following reproducibility and software design principles. We provide implementations of all methods included in the benchmark as well as results computed over 100 TPU days, 20 GPU days, 400 hyperparameter configurations, and evaluation on at least 6 random seeds each.
@inproceedings{band2021benchmarking,title={{B}enchmarking {B}ayesian {D}eep {L}earning {o}n {D}iabetic {R}etinopathy {D}etection {T}asks},author={Band, Neil and Rudner, Tim G. J. and Feng, Qixuan and Filos, Angelos and Nado, Zachary and Dusenberry, Michael W. and Jerfel, Ghassen and Tran, Dustin and Gal, Yarin},booktitle={Advances in Neural Information Processing Systems 34},year={2021},}
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
Zachary Nado, Neil Band, Mark Collier, Josip Djolonga, Michael W. Dusenberry, Sebastian Farquhar, Angelos Filos, Marton Havasi, Rodolphe Jenatton, Ghassen Jerfel, Jeremiah Liu, Zelda Mariet, Jeremy Nixon, Shreyas Padhy, Jie Ren, Tim G. J. Rudner, Yeming Wen, Florian Wenzel, Kevin Murphy, D. Sculley, Balaji Lakshminarayanan, Jasper Snoek, Yarin Gal, and Dustin Tran
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Additionally we provide model checkpoints, experiment outputs as Python notebooks, and leaderboards for comparing results.
@inproceedings{nado2021uncertaintybaselines,author={Nado, Zachary and Band, Neil and Collier, Mark and Djolonga, Josip and Dusenberry, Michael W. and Farquhar, Sebastian and Filos, Angelos and Havasi, Marton and Jenatton, Rodolphe and Jerfel, Ghassen and Liu, Jeremiah and Mariet, Zelda and Nixon, Jeremy and Padhy, Shreyas and Ren, Jie and Rudner, Tim G. J. and Wen, Yeming and Wenzel, Florian and Murphy, Kevin and Sculley, D. and Lakshminarayanan, Balaji and Snoek, Jasper and Gal, Yarin and Tran, Dustin},title={{U}ncertainty {B}aselines: {B}enchmarks {f}or {U}ncertainty {&} {R}obustness {i}n {D}eep {L}earning},year={2021},booktitle={NeurIPS Workshop on Bayesian Deep Learning},}
On Signal-to-Noise Ratio Issues in Variational Inference for Deep Gaussian Processes
Tim G. J. Rudner*, Oscar Key*, Yarin Gal, and Tom Rainforth
International Conference on Machine Learning(ICML), 2021
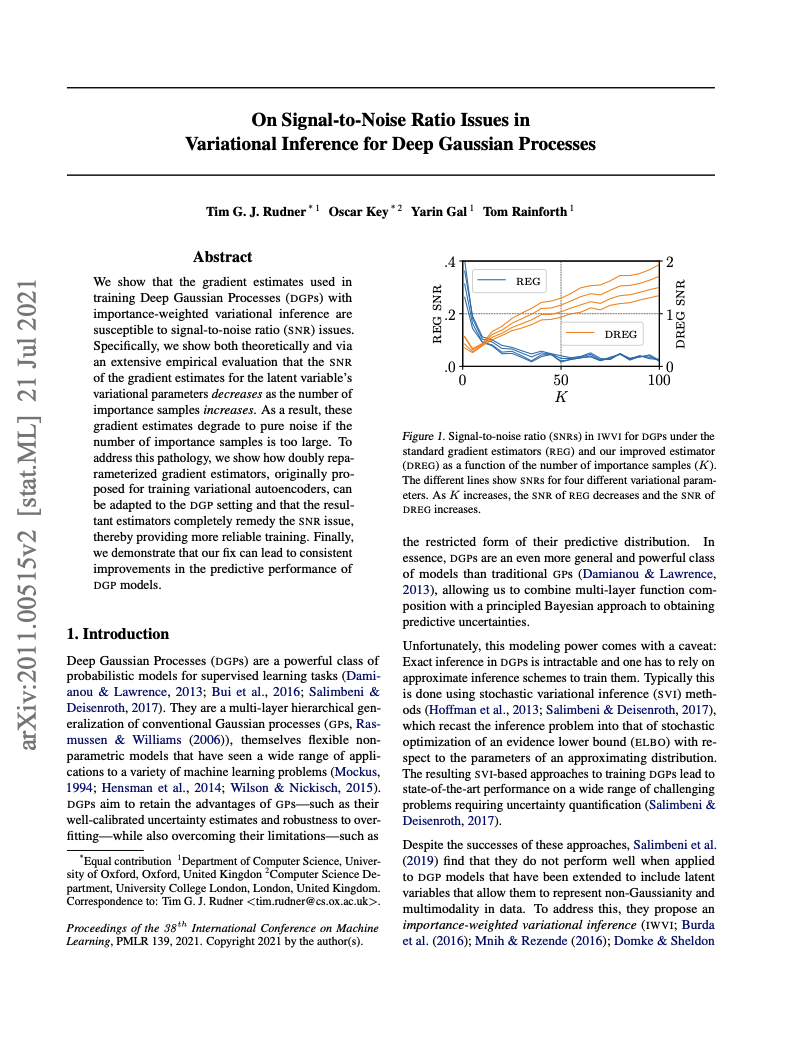
We show that the gradient estimates used in training Deep Gaussian Processes (DGPs) with importance-weighted variational inference are susceptible to signal-to-noise ratio (SNR) issues. Specifically, we show both theoretically and via an extensive empirical evaluation that the SNR of the gradient estimates for the latent variable’s variational parameters decreases as the number of importance samples increases. As a result, these gradient estimates degrade to pure noise if the number of importance samples is too large. To address this pathology, we show how doubly reparameterized gradient estimators, originally proposed for training variational autoencoders, can be adapted to the DGP setting and that the resultant estimators completely remedy the SNR issue, thereby providing more reliable training. Finally, we demonstrate that our fix can lead to consistent improvements in the predictive performance of DGP models.
@inproceedings{rudner2021snrissues,author={Rudner, Tim G. J. and Key, Oscar and Gal, Yarin and Rainforth, Tom},title={{O}n {S}ignal-to-{N}oise {R}atio {I}ssues in {V}ariational {I}nference for {D}eep {G}aussian {P}rocesses},booktitle={Proceedings of the 38th International Conference on Machine Learning},year={2021},series={Proceedings of Machine Learning Research},address={Online},publisher={PMLR},}
2020
Inter-domain Deep Gaussian Processes
Tim G. J. Rudner, Dino Sejdinovic, and Yarin Gal
International Conference on Machine Learning(ICML), 2020
Inter-domain Gaussian processes (GPs) allow for high flexibility and low computational cost when performing approximate inference in GP models. They are particularly suitable for modeling data exhibiting global structure but are limited to stationary covariance functions and thus fail to model non-stationary data effectively. We propose Inter-domain Deep Gaussian Processes, an extension of inter-domain shallow GPs that combines the advantages of inter-domain and deep Gaussian processes (DGPs), and demonstrate how to leverage existing approximate inference methods to perform simple and scalable approximate inference using inter-domain features in DGPs. We assess the performance of our method on a range of regression tasks and demonstrate that it outperforms inter-domain shallow GPs and conventional DGPs on challenging large-scale real-world datasets exhibiting both global structure as well as a high-degree of non-stationarity.
@inproceedings{rudner2020interdomaindgps,author={Rudner, Tim G. J. and Sejdinovic, Dino and Gal, Yarin},title={{I}nter-domain {D}eep {G}aussian {P}rocesses},booktitle={Proceedings of the 37th International Conference on Machine Learning},year={2020},volume={119},series={Proceedings of Machine Learning Research},address={Online},publisher={PMLR},}
2019
VIREL: A Variational Inference Framework for Reinforcement Learning
Matthew Fellows, Anuj Mahajan, Tim G. J. Rudner, and Shimon Whiteson
Advances in Neural Information Processing Systems(NeurIPS), 2019
Applying probabilistic models to reinforcement learning (RL) enables the application of powerful optimisation tools such as variational inference to RL. However, existing inference frameworks and their algorithms pose significant challenges for learning optimal policies, e.g., the absence of mode capturing behaviour in pseudo-likelihood methods and difficulties learning deterministic policies in maximum entropy RL based approaches. We propose VIREL, a novel, theoretically grounded probabilistic inference framework for RL that utilises a parametrised action-value function to summarise future dynamics of the underlying MDP. This gives VIREL a mode-seeking form of KL divergence, the ability to learn deterministic optimal polices naturally from inference and the ability to optimise value functions and policies in separate, iterative steps. In applying variational expectation-maximisation to VIREL we thus show that the actor-critic algorithm can be reduced to expectation-maximisation, with policy improvement equivalent to an E-step and policy evaluation to an M-step. We then derive a family of actor-critic methods from VIREL, including a scheme for adaptive exploration. Finally, we demonstrate that actor-critic algorithms from this family outperform state-of-the-art methods based on soft value functions in several domains.
@inproceedings{fellows2019virel,author={Fellows, Matthew and Mahajan, Anuj and Rudner, Tim G. J. and Whiteson, Shimon},title={{VIREL}: {A} {V}ariational {I}nference {F}ramework for {R}einforcement {L}earning},booktitle={Advances in Neural Information Processing Systems 32},year={2019},}
The Natural Neural Tangent Kernel: Neural Network Training Dynamics under Natural Gradient Descent
Tim G. J. Rudner, Florian Wenzel, Yee Whye Teh, and Yarin Gal
@inproceedings{rudner2019naturalntk,author={Rudner, Tim G. J. and Wenzel, Florian and Teh, Yee Whye and Gal, Yarin},title={{T}he {N}atural {N}eural {T}angent {K}ernel: {N}eural {N}etwork {T}raining {D}ynamics {u}nder {N}atural {G}radient {D}escent},booktitle={NeurIPS Workshop on Bayesian Deep Learning},year={2019},}
A Systematic Comparison of Bayesian Deep Learning Robustness in Diabetic Retinopathy Tasks
Angelos Filos, Sebastian Farquhar, Aidan N. Gomez, Tim G. J. Rudner, Zachary Kenton, Lewis Smith, Milad Alizadeh, Arnoud Kroon, and Yarin Gal
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods’ robustness and scalability, assessing whether new tools give ‘better’ uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on \emphdiabetic retinopathy diagnosis. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening—i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-domain to reflect real-world use of model uncertainty in automated diagnosis. We develop multiple tasks that fall under this application, including out-of-distribution detection and robustness to distribution shift. We then perform a systematic comparison of well-tuned BDL techniques on the various tasks. From our comparison we conclude that some current techniques which solve benchmarks such as UCI ‘overfit’ their uncertainty to the dataset—when evaluated on our benchmark these underperform in comparison to simpler baselines. The code for the benchmark, its baselines, and a simple API for evaluating new BDL tools are made available.
@inproceedings{filos2019bdlb,author={Filos, Angelos and Farquhar, Sebastian and Gomez, Aidan N. and Rudner, Tim G. J. and Kenton, Zachary and Smith, Lewis and Alizadeh, Milad and de Kroon, Arnoud and Gal, Yarin},title={{A} {S}ystematic {C}omparison {o}f {B}ayesian {D}eep {L}earning {R}obustness in {D}iabetic {R}etinopathy {T}asks},year={2019},booktitle={NeurIPS Workshop on Bayesian Deep Learning},}
Multi³Net: Segmenting Flooded Buildings via Fusion of Multiresolution, Multisensor, and Multitemporal Satellite Imagery
Tim G. J. Rudner, Marc Rußwurm, Jakub Fil, Ramona Pelich, Benjamin Bischke, Veronika Kopackova, and Piotr Bilinski
AAAI Conference on Artificial Intelligence(AAAI), 2019
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods’ robustness and scalability, assessing whether new tools give ‘better’ uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on \emphdiabetic retinopathy diagnosis. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening—i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-domain to reflect real-world use of model uncertainty in automated diagnosis. We develop multiple tasks that fall under this application, including out-of-distribution detection and robustness to distribution shift. We then perform a systematic comparison of well-tuned BDL techniques on the various tasks. From our comparison we conclude that some current techniques which solve benchmarks such as UCI ‘overfit’ their uncertainty to the dataset—when evaluated on our benchmark these underperform in comparison to simpler baselines. The code for the benchmark, its baselines, and a simple API for evaluating new BDL tools are made available at this https URL.
@inproceedings{rudner2019multi3net,author={Rudner, Tim G. J. and Rußwurm, Marc and Fil, Jakub and Pelich, Ramona and Bischke, Benjamin and Kopackova, Veronika and Bilinski, Piotr},title={{M}ulti{³}{N}et: {S}egmenting {F}looded {B}uildings via {F}usion of {M}ultiresolution, {M}ultisensor, and {M}ultitemporal {S}atellite {I}magery},booktitle={Proceedings of the Thirty-Three {AAAI} Conference on Artificial Intelligence},year={2019},}
The StarCraft Multi-Agent Challenge
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder Witt, Gregory Farquhar, Nantas Nardelli, Tim G. J. Rudner, Chia-Man Hung, Philip H. S. Torr, Jakob Foerster, and Shimon Whiteson
International Conference on Autonomous Agents and MultiAgent Systems(AAMAS), 2019
In the last few years, deep multi-agent reinforcement learning (RL) has become a highly active area of research. A particularly challenging class of problems in this area is partially observable, cooperative, multi-agent learning, in which teams of agents must learn to coordinate their behaviour while conditioning only on their private observations. This is an attractive research area since such problems are relevant to a large number of real-world systems and are also more amenable to evaluation than general-sum problems. Standardised environments such as the ALE and MuJoCo have allowed single-agent RL to move beyond toy domains, such as grid worlds. However, there is no comparable benchmark for cooperative multi-agent RL. As a result, most papers in this field use one-off toy problems, making it difficult to measure real progress. In this paper, we propose the StarCraft Multi-Agent Challenge (SMAC) as a benchmark problem to fill this gap. SMAC is based on the popular real-time strategy game StarCraft II and focuses on micromanagement challenges where each unit is controlled by an independent agent that must act based on local observations. We offer a diverse set of challenge maps and recommendations for best practices in benchmarking and evaluations. We also open-source a deep multi-agent RL learning framework including state-of-the-art algorithms. We believe that SMAC can provide a standard benchmark environment for years to come. Videos of our best agents for several SMAC scenarios are available at: this https URL.
@inproceedings{samvelyan19smac,author={Samvelyan, Mikayel and Rashid, Tabish and de Witt, Christian Schroeder and Farquhar, Gregory and Nardelli, Nantas and Rudner, Tim G. J. and Hung, Chia-Man and Torr, Philip H. S. and Foerster, Jakob and Whiteson, Shimon},title={{T}he {S}tar{C}raft {M}ulti-{A}gent {C}hallenge},booktitle={Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems},year={2019},}
Policy Reports & Issue Briefs
2024
Key Concepts in AI Safety: Reliable Uncertainty Quantification in Machine Learning
@inproceedings{rudner2023uncertainty,author={Rudner, Tim G. J. and Toner, Helen},title={{K}ey {C}oncepts in {AI} {S}afety: {R}eliable {U}ncertainty {Q}uantification in {M}achine {L}earning},booktitle={CSET Issue Briefs (Forthcoming)},year={2024},}
2022
OECD Framework for the Classification of AI systems
As artificial intelligence (AI) integrates all sectors at a rapid pace, different AI systems bring different benefits and risks. In comparing virtual assistants, self-driving vehicles and video recommendations for children, it is easy to see that the benefits and risks of each are very different. Their specificities will require different approaches to policy making and governance. To help policy makers, regulators, legislators and others characterise AI systems deployed in specific contexts, the OECD has developed a user-friendly tool to evaluate AI systems from a policy perspective. It can be applied to the widest range of AI systems across the following dimensions: People & Planet; Economic Context; Data & Input; AI Model; and Task & Output. Each of the framework’s dimensions has a subset of properties and attributes to define and assess policy implications and to guide an innovative and trustworthy approach to AI as outlined in the OECD AI Principles.
@inproceedings{oecd2022classification,author={{(as a contributing author)}, OECD},title={OECD Framework for the Classification of AI systems},booktitle={{OECD} {D}igital {E}conomy {P}apers},year={2022},number={323},doi={https://doi.org/https://doi.org/10.1787/cb6d9eca-en},}
2021
Key Concepts in AI Safety: Specification in Machine Learning
This paper is the fourth installment in a series on "AI safety," an area of machine learning research that aims to identify causes of unintended behavior in machine learning systems and develop tools to ensure these systems work safely and reliably. The first paper in the series, “Key Concepts in AI Safety: An Overview,” outlined three categories of AI safety issues—problems of robustness, assurance, and specification—and the subsequent two papers described problems of robustness and assurance, respectively. This paper introduces specification as a key element in designing modern machine learning systems that operate as intended.
@inproceedings{rudner2021specification,author={Rudner, Tim G. J. and Toner, Helen},title={{K}ey {C}oncepts in {AI} {S}afety: {S}pecification in {M}achine {L}earning},booktitle={CSET Issue Briefs},year={2021},}
Key Concepts in AI Safety: Interpretability in Machine Learning
This paper is the third installment in a series on "AI safety," an area of machine learning research that aims to identify causes of unintended behavior in machine learning systems and develop tools to ensure these systems work safely and reliably. The first paper in the series, “Key Concepts in AI Safety: An Overview,” described three categories of AI safety issues: problems of robustness, assurance, and specification. This paper introduces interpretability as a means to enable assurance in modern machine learning systems.
@inproceedings{rudner2021interpretability,author={Rudner, Tim G. J. and Toner, Helen},title={{K}ey {C}oncepts in {AI} {S}afety: {I}nterpretability in {M}achine {L}earning},booktitle={CSET Issue Briefs},year={2021},}
Key Concepts in AI Safety: Robustness and Adversarial Examples
This paper is the second installment in a series on "AI safety," an area of machine learning research that aims to identify causes of unintended behavior in machine learning systems and develop tools to ensure these systems work safely and reliably. The first paper in the series, “Key Concepts in AI Safety: An Overview,” described three categories of AI safety issues: problems of robustness, assurance, and specification. This paper introduces adversarial examples, a major challenge to robustness in modern machine learning systems.
@inproceedings{rudner2021robustness,author={Rudner, Tim G. J. and Toner, Helen},title={{K}ey {C}oncepts in {AI} {S}afety: {R}obustness and {A}dversarial {E}xamples},booktitle={CSET Issue Briefs},year={2021},}
This paper is the first installment in a series on "AI safety," an area of machine learning research that aims to identify causes of unintended behavior in machine learning systems and develop tools to ensure these systems work safely and reliably. In it, the authors introduce three categories of AI safety issues: problems of robustness, assurance, and specification. Other papers in this series elaborate on these and further key concepts.
@inproceedings{rudner2021aisafety,author={Rudner, Tim G. J. and Toner, Helen},title={{K}ey {C}oncepts in {AI} {S}afety: {A}n {O}verview},booktitle={CSET Issue Briefs},year={2021},}